The Tangled Love-Hate Story of Infrastructure as Code
What motivated me to write this post is not a particularly pleasant story. It’s true that I haven’t worked in industry for a while, as I’ve spent the past few years focusing on becoming an independent researcher. This post serves as a small piece of evidence for those who might question whether I still have the background knowledge or the ability to pick up practical engineering skills. Another reason comes from my experience working as a DevOps engineer. The work itself never gave me a headache: learning new frameworks and tools, building delivery pipelines, and configuring end-to-end integrations were all manageable. However, the job could sometimes feel frustrating. The quality of such work is difficult to measure and often receives little attention, so it is taken less seriously than the service or product it supports.
Although this write-up is partly motivated by these negative memories, my main goal is to highlight the importance of IaC. IaC can be annoying at times, but it is essential for modern system deployment. We should also avoid treating it as just another trendy buzzword 😮💨– notably cloud, big data, or AI – that people throw around without much thought. Another heads-up is that, this post will not go into other related topics like DevOps or CI/CD, so that the discussion can stay focused on IaC itself.
What is Infrastructure as Code (IaC)?
Literally speaking, IaC means “building infrastructure in the same way we write code”. That immediately raises two questions: why and how?
You may ask, what is "infrastructure"?
According to Dictionary.com, one definition of infrastructure is
the fundamental facilities and systems serving a country, city, or area, as transportation and communication systems, power plants, and schools.
So what does infrastructure mean in computing? For an IT service, like Netflix, what are the fundamental elements that make large-scale video streaming possible?
Taking the school as a useful analogy: its purpose is to educate students, but for a school to function, it needs a physical location, buildings, qualified teachers, and operating rules such as course schedules and graduation requirements. Likewise, the infrastructure behind an IT service includes hardware (computing resources and networking components), software (operating systems and databases), and the libraries, system configurations, and design decisions that support applications running.
Why?
To answer the first question, why IaC exists, we should first ask: how difficult is it to build infrastructure from scratch? Let’s make the question simpler, but also a bit more concrete: when was the last time you installed an operating system yourself?
Most of the time, the process feels straightforward because common installers provide a
friendly graphical interface:
we simply click Next or Yes until the installation finishes,
much like installing a regular application.
But behind those clicks, we are still making infrastructure-level decisions:
creating user accounts, setting hostnames and gateway addresses,
defining storage partitions, and choosing which system-level libraries or daemons (e.g. compilers or SSH services)
should be installed.
Now imagine doing the same thing not for a single machine, but for an entire cluster.
At that point, the challenge is no longer just technical know-how;
it becomes a repetitive and error-prone operational burden 😰.
This naturally leads to a simple idea: what if we automate it? To make that possible, we first need to describe these configurations in 1) a structured form, and then 2) develop tools that can interpret and apply them consistently. Beyond simply automating infrastructure setup, some additional advantages immediately emerge:
Human error reduction: Automation doesn’t just bring speed (and a coffee break). It reduces mistakes from hand-operated clicks and command typing.
Version control: Once infrastructure is written in human-readable, code-like form, it can be versioned with tools like Git. Bugs won’t disappear, but now you
find out who did it 😈have history to debug, roll back, and support auditing.Delivery and reproducibility: IaC can be shipped and deployed across environments. Could scripts do this? Sure, but their high flexibility makes them harder to read, and usually requires manual steps to run like copying files or pushing remote commands line by line. Not exactly hands-free.
Scalability: The limitations of scripts show up quickly at scale. With IaC, spinning up or tearing down multiple nodes becomes fast and consistent. By the way, that’s a core idea behind cloud computing.
How?
To make IaC work, it requires executable components on the target systems so they can access and manage resources when building infrastructure. These execution units, as binaries or agents, need to be able to:
- Validate configuration files
- Respond to client requests
- Communicate with controllers or other nodes
- Execute operations, including provisioning infrastructure based on the defined configurations
Do not assume a single system design here. These functions and workflows are not implemented and operated in the same way. Different IaC tools adopt different approaches. Thus, for communication (point 2), some tools embed their own protocols, others rely on third-party APIs or plugins, and some simply use SSH. We will look at these variations later.
IaC Tools in Practice
Before introducing some IaC solutions, it is useful to first evaluate the main procedures involved in deploying a system service. This helps clarify what IaC tools should be responsible for in practice.
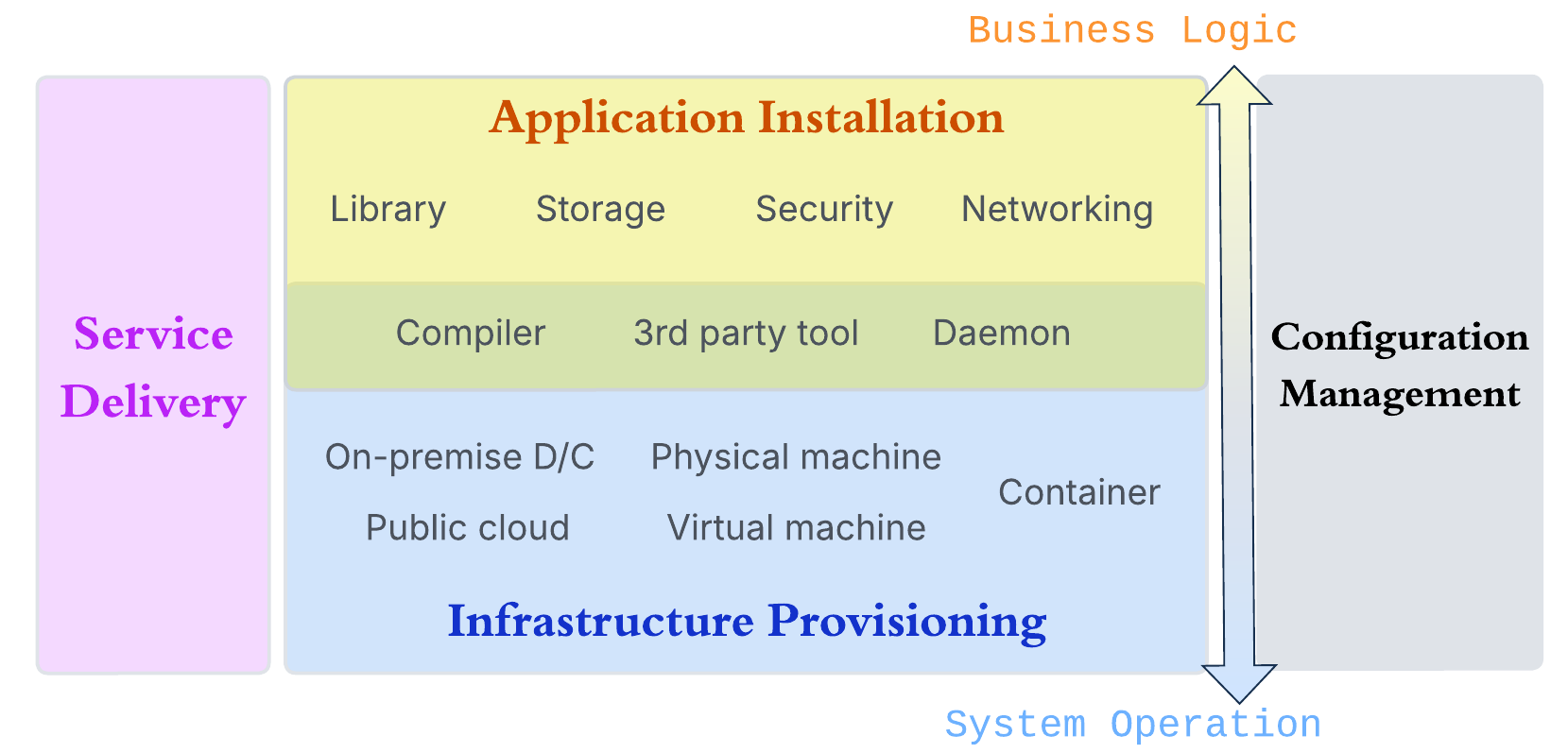
The diagram illustrates four modules arranged vertically to represent the software stack, while the horizontal grouping highlights different functional concerns.
The management ownership
In the middle section, the blue block at the bottom represents infrastructure provisioning. This process goes beyond simply creating compute instances; it also includes configuring them for explicit roles. For example, a node may be provisioned as a database server with a defined amount of storage, also, a group of nodes may require network isolation for security, possibly with controlled access through a proxy.
Above it, the yellow block represents application setup. At first glance, some configurations, such as networking and storage, appear to overlap with those in the infrastructure layer. The key distinction lies in ownership and scope of management.
Infrastructure provisioning is responsible for the underlying resources and shared capabilities across applications. In contrast, application setup takes care of configurations specific to the workload itself. As a result, removing an application or its configurations should not delete or release the underlying infrastructure resources. As indicated by the double-headed arrow in the figure, these two modules have different focuses: the application layer targets on business logic and service behavior, in the same time, the lower layers of the stack handle on system-level operations and resource management.
An example use-case table may provide a clear picture:
| Deployment layer | Storage | Networking |
|---|---|---|
| Application Installation | Create a models directory and download the required model files | Assign the hostname api-homeland.io to the API server |
| Infrastructure Provision | Allocate and format an ext4 disk volume | Create a subnet 10.0.1.0/24 |
Beyond deployment
The other two modules, service delivery and configuration management,
span the entire software stack, rather than belonging to a single layer.
Why are they involved? In fact, they already exist even when a system is deployed manually.
Instructions like bring the system online at 5 PM
or
run the script with this set of parameters
are informal forms of these processes.
As the IaC ecosystem matures, these responsibilities become formalized and more systematic.
Configuration management is not simply maintaining plain-text IaC files across environments (e.g., production, staging, and testing). It also covers handling sensitive data like credentials, as well as coordinating configurations across projects or organizations that share resources. This added complexity often makes IaC codebases harder to manage than conventional application code.
Service delivery is typically realized through CI/CD systems. It defines the pipeline for building both application and infrastructure code, running unit and integration tests, injecting the required configurations, and controlling execution flow, e.g., when to trigger deployments and how to roll back if failures occur.
Where does IaC really fit in?
IaC tools primarily cover the infrastructure provisioning layer (the blue and green blocks) and may also participate in parts of configuration management.
True that there is still a blurred boundary with application installation. As discussed earlier, infrastructure provisioning manages resources. The green area that overlaps with the application layer reflects certain software components are treated as resources. For instance, IaC can manage the installation and versioning of systems like Apache Airflow. Although application workloads depend on such systems, changes may trigger updates or redeployments of those workloads. We still classify these supporting softwares under IaC because they are shared across multiple applications and are not part of the application development lifecycle. In other words, they should not be rebuilt or removed with every application code change.
IaC files are often managed with version control systems like Git, but IaC tools also contribute to configuration management. They define standardized configuration formats and provide registries for reusable modules or templates, maintained by official sources or the community. These formats make infrastructure definitions more structured and separate configurable variables from resource abstractions. In addition, IaC tools provide syntax and interfaces to pass these variables dynamically during deployment, further improving consistency and manageability.
Introduction to some popular tools
Now comes the interesting part: a bit of gossip 🤩. I’ve sketched a timeline of several popular IaC tools alongside key milestones in the evolution of cloud systems.
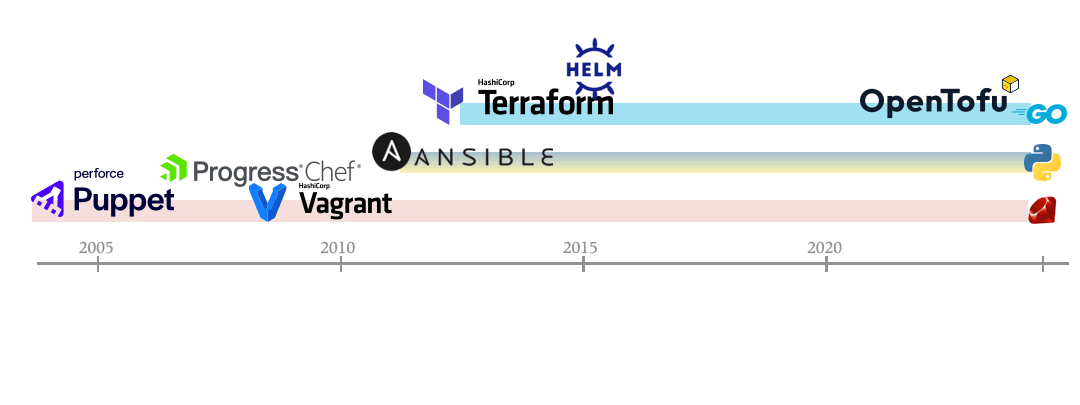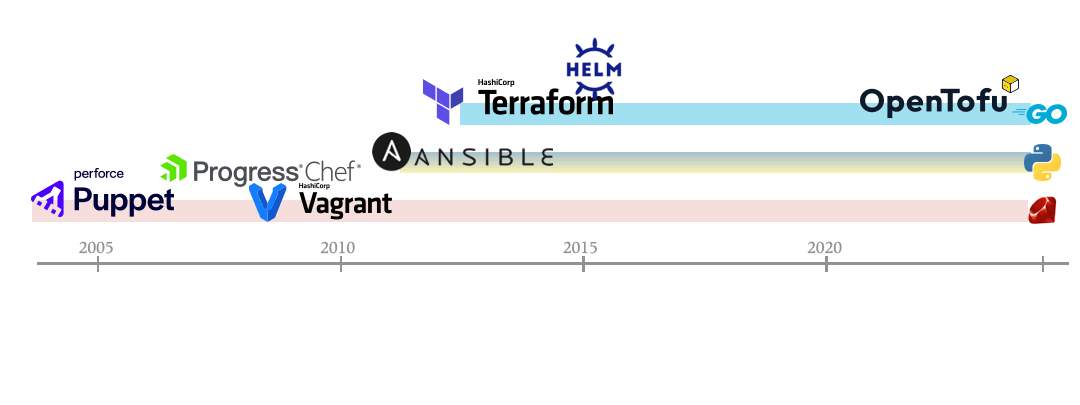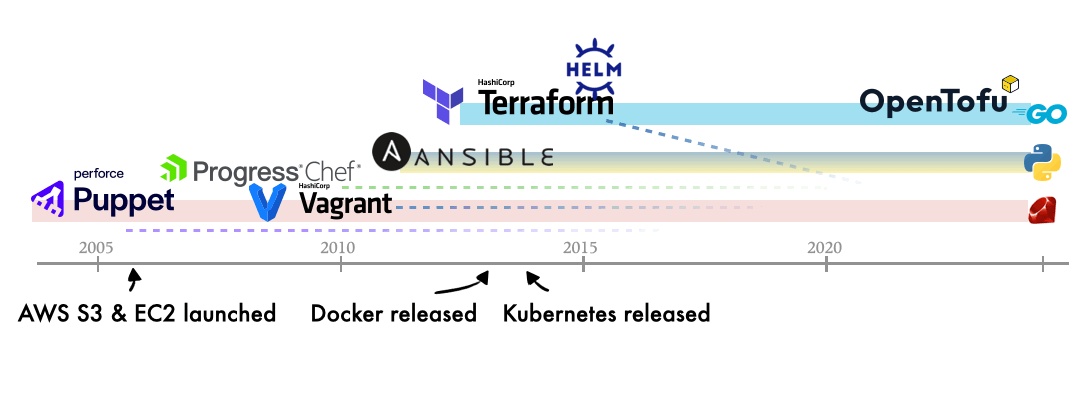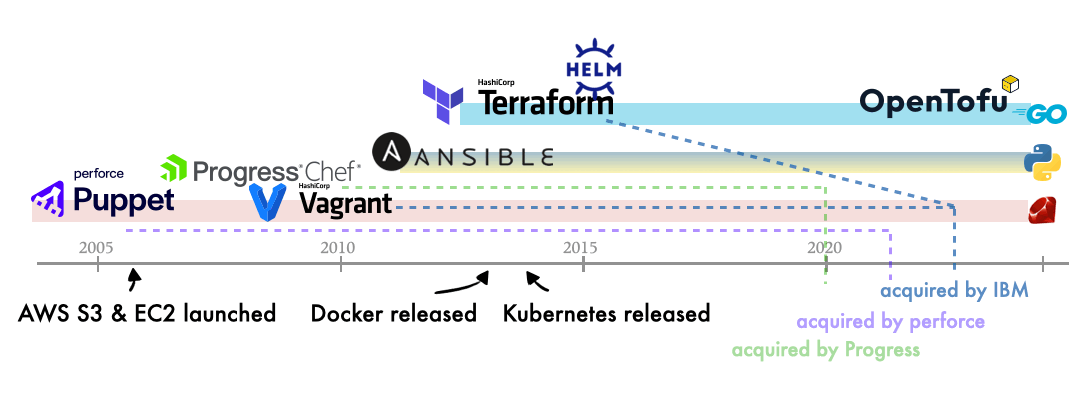
A few observations stand out from this timeline:
The implementation languages shift from Ruby to Go. Is this related to the rise of container technologies?
Early tools appear alongside emerging cloud services. Probably they complement each other and help scalability mature over time.
Pioneering tools have been acquired by bigger, more profitable companies in recent 5 years (maybe this is just a broader industry trend). It’s unfortunate, given that these projects maintained a clear vision for over a decade.
Helm was released shortly after Kubernetes. Does this suggest that IaC-style design became a norm in orchestration ecosystems?
Let’s look at a few representative tools. I select them because they play different roles across the IaC landscape.
Ansible
Continuing the “gossip”, you might wonder whether Ansible survived the wave of acquisitions. Not exactly. It was acquired by Red Hat only a few years after becoming a company itself, so it joined a big company quite early.
Ansible works similarly to tools like Puppet and Chef, In the deployment model, they mainly sit in the green layer, helping set up system software on target hosts. For orchestrating across multiple nodes, Ansible follows a server-client model: the control node handles requests and pushes commands to managed nodes. This pattern is common across many IaC tools.
What makes Ansible special is its agentless design. Managed nodes do not need a running agent or the installation of Ansible package. Instead, Ansible communicates over SSH (for Linux machines), which feels simple and convenient, right? However, this convenience is not entirely “free” on the managed node side. Nodes still need a working Python environment and properly configured SSH access: a dedicated user account with key-based authentication, where the password login must be disabled. At this point, a natural question arises: doesn’t this create a chicken-and-egg problem? If Ansible is meant to automate system setup, why do we need to prepare part of the environment manually in advance?
Terraform / OpenTofu
The previous question can be addressed at a lower layer by tools like Terraform. It operates closer to infrastructure provisioning, the blue block in the figure.
Before Terraform, Vagrant was the first product of Hashicorp, or, it led to the founding of the company. Vagrant is designed to interface with local hypervisors to create and manage virtual machines. Terraform follows a similar idea but at a broader scope. It defines infrastructure in a declarative format and applies that definition through resource providers. This model decentralizes execution: anyone with the Terraform environment, provider plugins, and permissions can provision and manage the same infrastructure from their ends. The standard IaC format serves as the unifying layer across different users and locations.
From another perspective, setting up a usable Terraform environment involves more than installing the CLI. You also need access to a resource pool, whether in a public cloud or a private data center. Yet, the appropriate provider plugins must be installed (available in the official registry), and credentials must be configured to access the target platform.
OpenTofu is a fork of Terraform, created after HashiCorp changed its liscense. Its architecture and core concepts still apply. OpenTofu maintains its own registry for providers and modules as well.
Helm
Is Helm really an IaC tool, even though it describes itself as a package manager?
It’s not straightforward to classify it as a general IaC tool.
First, Helm does not define a new infrastructure model or interface;
instead, it builds directly on Kubernetes. It relies on the kubeconfig,
uses Kubernetes APIs to manage resources, and defines part of its metadata and state through CRDs.
Furhermore, Helm operates strictly within a Kubernetes cluster.
So, does it actually create infrastructure, or does it simply deploy applications on top of an existing one?
Practically, Helm is capable for what we expect from IaC tools. It introduces charts, which define templates, separate configuration values, and specify deployment ordering. Helm also manages deployments through releases, offering a form of versioning and lifecycle control.
Okay, then, where does Helm sit in the deployment model? It arguably spans both the blue and green layers. Helm can create and manage resources such as Pods, Services, and Volumes, and it is commonly used to deploy system-level components, e.g., a tracing system. Even core Kubernetes components, for instance, the CNI plugins, can be installed via Helm charts. At a higher level, this dual role comes from Kubernetes itself. Kubernetes effectively software-izes infrastructure by representing resources like storage and networking as API objects. As a result, Helm operates on infrastructure abstractions, even though it runs within the system. From this perspective, Helm can reasonably be seen as an IaC tool – one that works through the abstractions provided by Kubernetes.
Are We Creating Harmony or Chaos?
Many blog posts at this point would start introducing best practices for using IaC tools. I don’t fully agree with that, because there is no single best setup that fits all environments, the scale of systems and workloads vary too much. Instead, going back to the title: if IaC tools are so elegant and useful, why can working with them still feel painful? Let’s look at some situations.
Mixed ownership across tools and orchestrations
Turning infrastructure into code makes its complexity visible (probably not a good thing). Even with a single tool, templates can become messy. What happens when multiple tools are involved? Imagine reviewing a codebase written in several languages and frameworks at once, what a mess!
One issue is overlapping ownership, where the same resources or configurations are managed by multiple tools. For example, using Ansible to provision VMs and install the OS1 (which is actually not a simple or clean approach). Or creating containers with Terraform2 while still relying on Kubernetes or Docker Swarm. At that point, it becomes unclear who is responsible for the final state.
IaC applied to application lifecycle
We generally agree that IaC tools are meant for infrastructure.
But, have you seen that the application build logic is embedded in IaC templates?
running docker build, docker run, or even make.
Yes, it works, but why do this?
IaC tools are not designed to handle build failures, retries, or rollbacks.
Some argue that keeping everything in one format improves consistency. Fine, but consider this:
- name: Start application
hosts: app_servers
tasks:
- name: Run app in backend
ansible.builtin.shell: nohup ./start.sh &The actual logic are still concealed inside scripts. Nothing is really improved. What’s worse, bugs become harder to trace. Is the issue in the IaC template, the build environment, the Makefile, or the application itself? This example is even a nightmare – since it runs as a background process, nothing is returned.
Using other tools to generate or manage IaC templates
There is always a learning curve between knowing a tool and using it well. In many cases, not limited to IaC, people try to save time by introducing helper tools on top of others. The problem is the hidden cost, as discussed earlier in my complaint about container misuse. Similar patterns appear in tools like Anaconda and CMake. For example, Terraform provides an official Helm provider. This not only shows how a IaC management become more complex, but also highlights a common illusion: you might think you’re skipping a step, but you still have to learn another.
Practices for humans
Don’t be too pessimistic after the discussion above. Tools are created to make our life easier. While I don’t want to prescribe best practices, I’d like to share a few princibles I keep in mind:
Understand the problem and the tool first: Blindly using whatever comes along or whatever sounds fashionable can cause trouble. A good tool is not always the right solution for a given problem.
Keep things simple: Simpler approaches are often more efficient: they use fewer resources, run faster, and are easier for others to understand. The same applies to communication: explain things as clearly and simply as possible. Complexity doesn’t make ideas better, and it won’t make you look better either.
Be clearly about what you’re doing: You don’t need to be 100% certain all the time, that can lead to becoming stubborn and rigid. And not everything in life has to be perfectly rational 😆. But in research and engineering work, decisions should be made carefully, based on sound judgment, when possible, supported with numbers. That’s part of being professional.
A Sorrowful Beginning, A Peaceful Ending
The first IaC tool I worked with was Vagrant, during the time working on the master thesis. Before that, I wrote Bash scripts to spawn VMs across dozens of physical nodes using libvirt, QEMU, and KVM (old-fashioned, right?). Vagrant made the process much cleaner and faster.
My second tool was AWS CloudFormation, in my first job after graduation. It was also my first time working with a public cloud. I still remember my probation task: build a tool to generate CloudFormation templates for other team members. Funny, doesn’t that sound like what I criticized earlier?
Later, I worked with Chef, and through it, I picked up some Ruby. Its naming is quite entertaining: recipes, cookbooks, knife, and supermarket. Worth a look for fun 🤣.
I understand how trivial, tedious and frustrating system management can be, and IaC automation is essential when building systems for continuous development, team collaboration, and production delivery. But the key takeaway is this: learning the IaC tools is not enough, you can’t skip the fundamentals of system deployment.
The reason I’m still here, not tired of it, is probably simple: I like systems. And that’s a story you hear quite often.
Author Carol Hsu
LastMod 2026-04-19 (c616107)
License All rights reserved. Feel free to reach out with any questions.